8.0 KiB
哪吒系统监控信息港与华严设备负载-王宇
| ID | Creation Date | Assignee | Status |
|---|---|---|---|
| GIT-74 | 2020-07-24T14:23:07.000+0800 | 王宇 | 完成 |
需求: 1、信息港、华严办公环境服务器添加入信息港哪吒系统内 2、服务器有现与使用人的对应关系 3、资源负载监控包括:系统CPU、MEM、硬盘消耗,报告出每一项损耗的TOP5,其他检测项后续补充;
以上监测要求在NEZHA做出对应的图表展示(panel); 4、有资源消耗负载导出功能;
5、提出使用NEZHA对虚拟资源进行监测的方案;
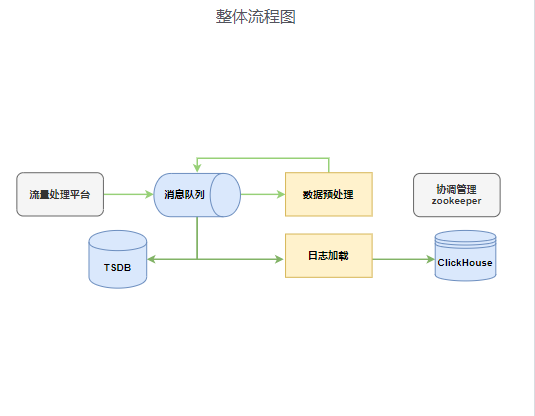
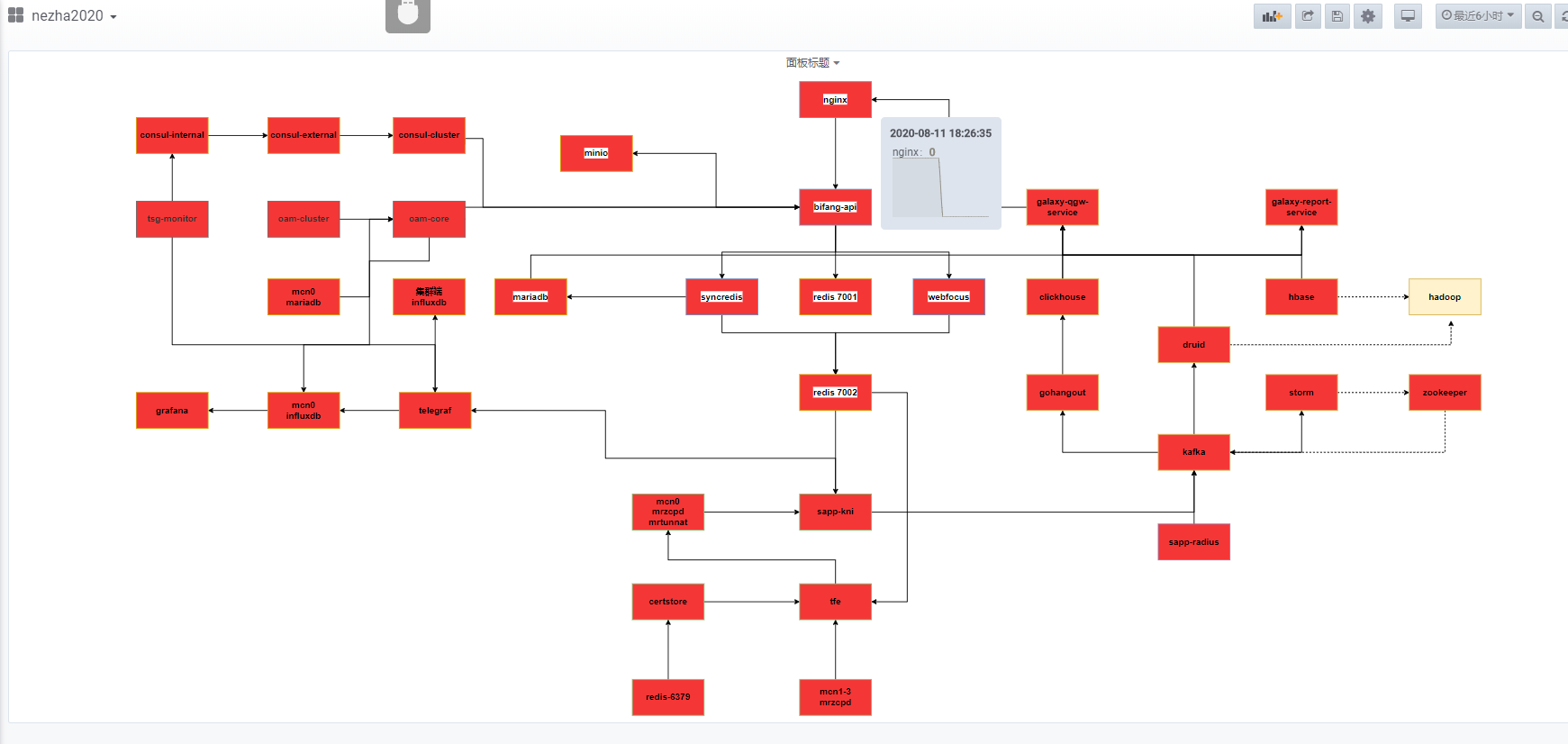
6、做出TSG整体的流程图,类似galaxy的整体流程图如下
!image-2020-07-24-16-20-50-777.png!
注: 1、服务器列表与机架位置详细信息由[~chenglei]、[~yangyang]、[~yinfutao]配合确定 2、检测项及需求由[~fangshunjian]提供支持 3、及时更新进度huangyuanyuan commented on 2020-07-24T15:28:29.705+0800:
麻烦知道的人,在本ISSUE备注出本套NEZHA的访问地址[~majingxue]
majingxue commented on 2020-07-24T15:43:24.422+0800:
[~huangyuanyuan]好,目前信息港NEZHA登录界面URL为:http://192.168.40.118/#/login 系统部署情况由[~wangyu]补充,后续若有变动会及时更新。
wangyu commented on 2020-07-28T20:10:40.047+0800:
工作进度:
目前Assets信息港数据中心服务器添加完毕共61台。有5台ping不通,需要确认原因。华严数据中心服务器添加完毕共35台。有9台ping不通,需要确认原因。
交换机目前没有ip,过一段时间添加。
wangyu commented on 2020-07-29T21:08:21.664+0800:
工作进度:
目前正在确认华严几台机器的用户名和密码。
集群40.117的prometheus不正常,Projects无法获取到数据,正在处理。
wangyu commented on 2020-07-31T13:44:29.680+0800:
工作进度:
1. 信息港、华严服务器已添加到信息港哪吒系统内,资产类型参数也重新做过调整。在资产标签中添加了使用人、所属部门、UUID等,后期资产名称会更改为单位的资产编号,标签中还会添加资产所属的单位。
-
cpu、mem、硬盘使用情况已监控,已在nezha形成图表。
-
nezha对虚拟机资源的监控方案:方案1.在资产添加中可以添加0U位置的主机,这样直接对主机进行监控。方案2. 单独创建一个专属虚拟机的机柜1-128(U),创建一个内存多大的虚拟机就在机柜写几U。
目前存在的问题:
1. 目前cpu、mem、硬盘使用情况只对信息港的服务器进行了监控,华严还需要一个prometheus监控节点,目前刚在华严创建了一个虚拟机,我正在安装prometheus监控节。
-
信息港有两台40.27和40.28服务器无发启动nezha插件,我目前还在研究原因,后期可能需要开发的帮助。
-
华严有些机器挂了所以ping不通,目前程磊和高明月在处理。
wangyu commented on 2020-07-31T13:49:48.261+0800:
根据目前存在的问题和需要一一确认每台服务器的SN码,完成时间需要延期。
wangyu commented on 2020-08-03T21:08:34.932+0800:
工作进度:
对华严节点的prometheus进行了部署。
华严机器目前有3个ip没有用户名密码,所以无法远程监控。程磊正在查找。
对信息港服务器的使用人进行了更新。
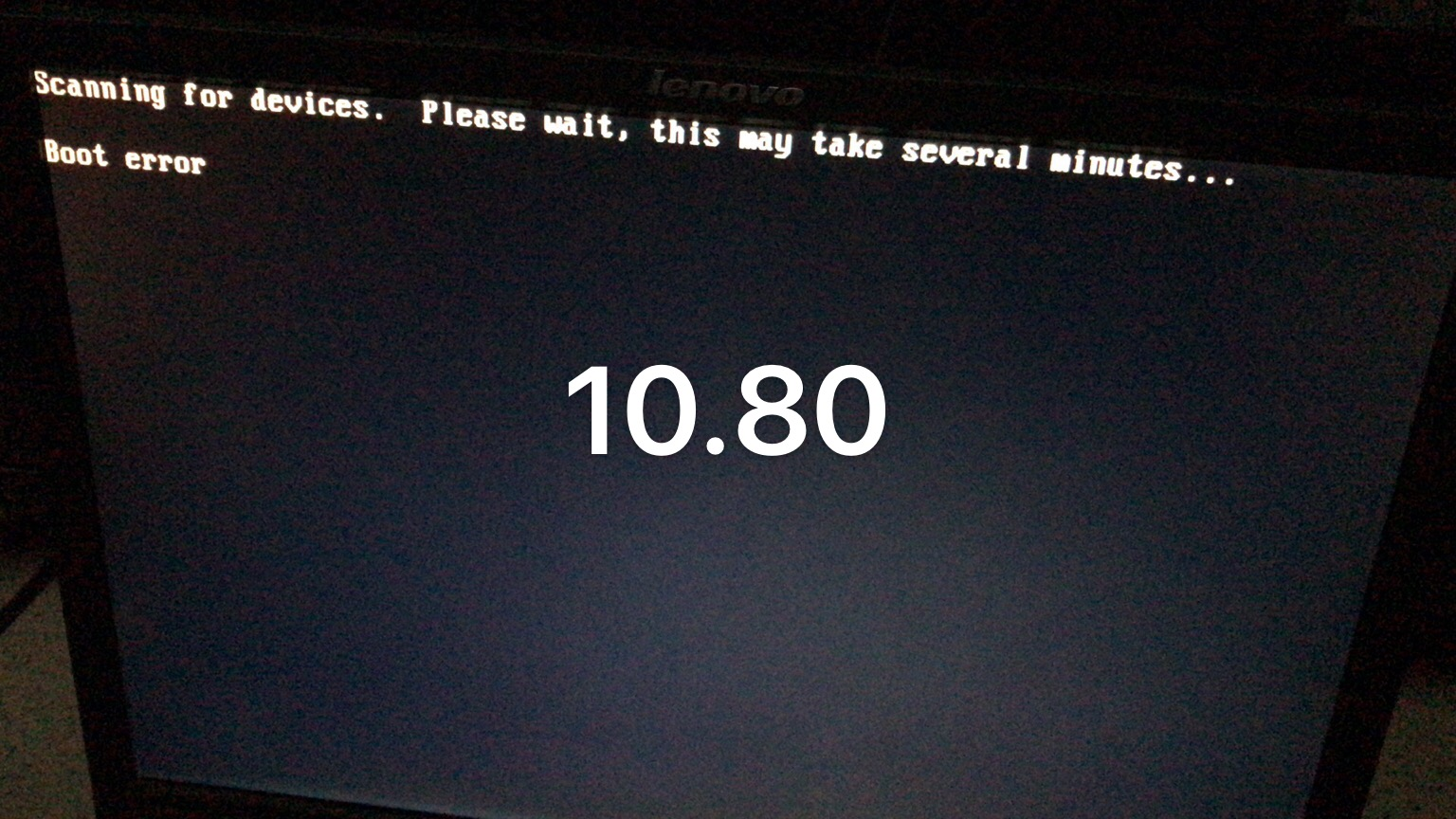
华严10.80服务器有启动错误,无法正常启动,问题已经报告程磊。 !image-2020-08-03-20-56-40-033.png|width=448,height=252!
40.27和40.28目前还是有问题,我正在处理。
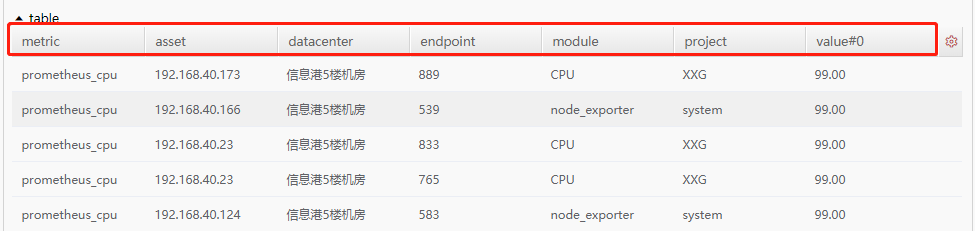
nezha监控表格目前只能对已有的参数进行配置,目前无法新增。 !image-2020-08-03-21-08-01-324.png|width=663,height=157!
wangyu commented on 2020-08-05T02:16:58.967+0800:
今天处理机房网络,没有处理nezha。
majingxue commented on 2020-08-05T11:36:13.176+0800:
异常服务器处理需要时长,先延期到8月15日,后续整理好需要开发内容,根据开发周期进行延期
wangyu commented on 2020-08-05T20:04:57.993+0800:
工作进度:
编辑了监控脚本,新添加了磁盘IO、服务器用户登录日志的监控和mysql、redis、api的服务保活报警。
华严服务器11.242硬件故障,目前杨阳正在上报。10.80需要重装系统。剩余服务器以及正常。
添加服务器用户登录日志时发现有大量124.28IP在8月2日凌晨时登录服务器失败信息。公司90%的服务器登录日志都有124.28的登录失败记录。
wangyu commented on 2020-08-06T19:04:06.055+0800:
工作进度:
华严服务器11.242已经正常。
添加虚拟机监控,目前正在40.117上部署telegraf+influxdb+grafana架构。通过telegraf的vsphere插件对虚拟机进行监控。
遇见的问题:
1. telegraf启动正常后无法往influxdb写入数据,目前还在寻找原因。
2. 监控发现40.118一直在连接40.131,目前还在寻找原因。
wangyu commented on 2020-08-08T03:57:02.590+0800:
工作进度:
部署telegraf+influxdb+grafana架构。
解决40.118一直连接40.131的问题。问题原因:配置文件中缺少参数。
遇见问题:
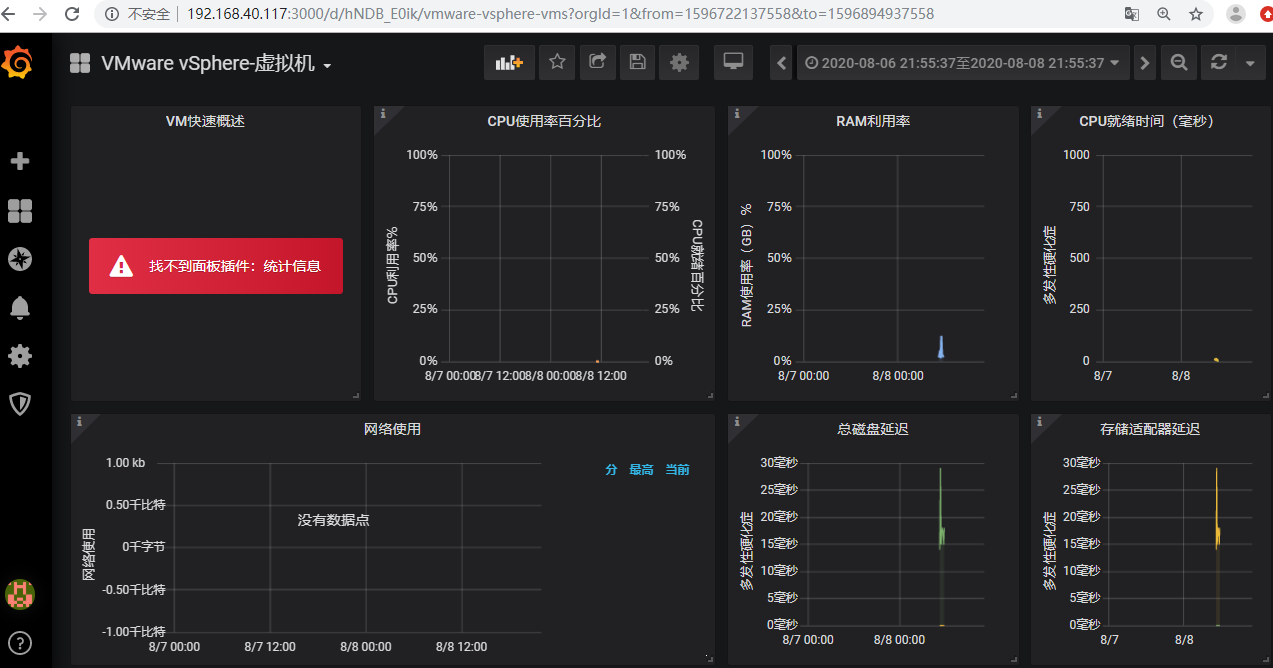
1. telegraf运行后采集的虚拟机数据与现实时间不同。报错:Error: ServerFaultCode: A specified parameter was not correct: entity,目前还在查找原因。
尝试解决办法:1. 同步esxi时间。2. 修改telegraf.conf配置文件。
!image-2020-08-08-03-56-43-959.png|width=432,height=227!
wangyu commented on 2020-08-10T21:16:44.774+0800:
工作进度:
1. telegraf+influxdb+grafana部署完毕。telegraf采集的数据时间问题已解决。 !image-2020-08-10-21-14-17-035.png|width=489,height=249!
- 目前正在把TSG软件流程图做成动态监控模式。
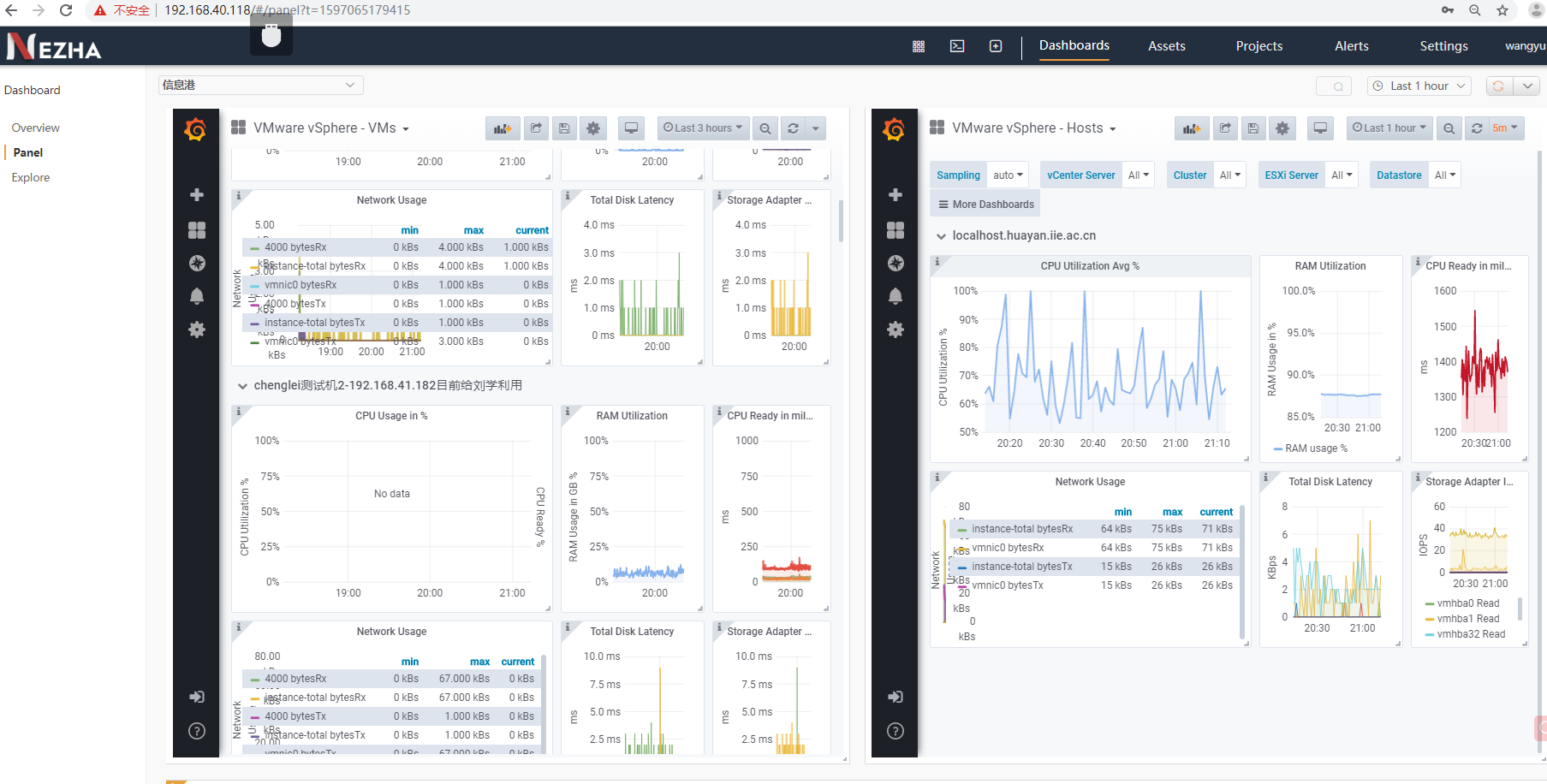
wangyu commented on 2020-08-11T18:29:53.828+0800:
工作进度:
目前grafana模板编辑完毕,还需要编辑监控脚本,传输正确的监控数据。 !image-2020-08-11-18-29-30-986.png|width=664,height=315!
wangyu commented on 2020-08-13T18:28:53.090+0800:
工作进度:
编辑流程图监控脚本。
编辑esxi系统监控文档。
编辑grafana制作流程图报警文档。
wangyu commented on 2020-08-14T19:21:44.821+0800:
工作总结:
部署nezha。
严和信息港主机。
添加监控指标。
监控esxi虚拟机。
实现tsg流程图监控。
nezha添加登录用户。
[^任务总结.docx]
Attachments
Attachment: image-2020-07-24-16-20-50-777.png
Attachment: image-2020-08-03-20-56-40-033.png
Attachment: image-2020-08-03-21-08-01-324.png
Attachment: image-2020-08-08-03-56-43-959.png
Attachment: image-2020-08-10-21-14-17-035.png
Attachment: image-2020-08-11-18-29-30-986.png
Attachment: 任务总结.docx